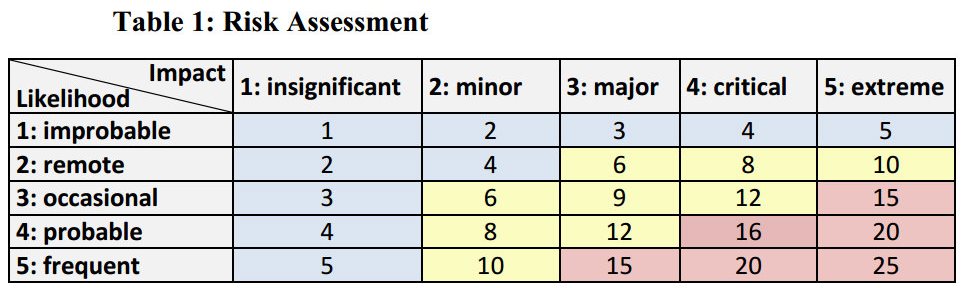
Материал заинтересовал меня, в первую очередь из-за таблицы ниже
С учетом того, что статистики (а российские, на генетическом уровне), мягко говоря, не любят все, что отличается от линейной зависимости, эти парни умудрились протащить использование функции активации в параболическом виде для определения степени риска использования BigData в официальной статистике. Молодцы. Естественно, статистики добавили свое примечание к этой работе – «1 Любые ошибки и упущения являются исключительной ответственностью авторов. Мнения, выраженные в этом документе, являются личными и не обязательно отражают официальную позицию Европейской комиссии». Но работу опубликовали. Думаю, на сегодня, этого достаточно, и они (авторы) никому не запрещали находить свои шкалы в этих аспектах.
В работе достаточно структурировано можно разделить, где и каким образом статистические методы отличаются от методов исследования для BigData. На мой взгляд, самая большая польза от этой работы будет при разговоре с заказчиком и для опровержения его высказываний типа:
— А мы собираем сами статистику, что Вы тут еще хотите исследовать?
— А вы нам свои результаты представьте так, чтобы мы их со своей статистикой согласовали. В этом вопросе авторы говорят, что неплохо бы почитать эту работу (3 How big is Big Data? Exploring the role of Big Data in Official Statistics)
В данной работе авторы проставили свое виденье уровня риска. Этот параметр стоит в скобках, не путать со ссылкой на источники.
Второе наблюдение. Авторы используют термин BDS – это аналог понятия BigData. (видимо реверанс официальной статистике).
Читать дальше →
Комментариев нет:
Отправить комментарий